参考论文:A Survey on Transfer Learning
1、Introduction
在机器学习和数据挖掘中有一个很普遍的假设就是训练数据和测试数据来源于统一特征空间并服从相同的分布。而当测试数据分布发生改变之后,我们又不得不从新收集同分布的训练数据并从新训练模型。这在真实的应用中去从很难去重新收集数据并建模,而且给原始数据人工标签的代价也很昂贵。在这些情况下,迁移学习可以很好的解决这些问题。
什么是迁移学习?用一句话概述就是基于已有的知识可以更快的学习新的知识。例如一个人会下象棋就会更容易地学会下围棋,一个人会说英语也就更容易学会西班牙语等。迁移学习强调的是在不同但是相似的领域、任务和分布之间进行知识的迁移。
迁移学习能应用的场景也很多。例如网络文档分类,我们将网络中的文档分入到预设定的几个类别中。我们用当时的网络文档打上标签训练分类模型,而对于现在新的网络文档,其数据特征和分布可能和当初训练模型时的训练数据不同,此时新的网络文档分类就会不准确。而从新收集训练数据并训练模型的成本又非常高,这种情况下,迁移学习就能很有帮助。另一个例子,我们在对相机的评价做情感分类时,不同品牌的相机的评价数据可能服从不同的分布,然而在训练模型时,我们又无法收集所有品牌的相机的评价数据,并打上相应的标签,这样的成本是很高的。通常情况下我们可以收集几种品牌的相机的评价数据并打上标签,用这些带标签的数据训练模型,之后可以通过迁移学习的方式将其迁移到其他品牌相机的情感分类问题上。
2、Overview
传统的机器学习和数据挖掘算法都是基于有监督或无监督训练后的统计模型来预测。无论怎样,在传统的机器学习中我们都认为训练数据和预测数据是服从同分布的。迁移学习其实和多分类问题有点类似,不过多分类问题是讲所有的任务同时进行的,即使这些任务的分布状态不同。而迁移学习可以根据早期的任务来应用到新的任务上。关于传统机器学习和迁移学习的区别如下图所示:

在上图中,传统的机器学习是讲源任务和目标任务放在一起同时学习的,而对于迁移学习是先学习源任务,然后从源任务中抽取相关的知识迁移到目标任务上。在这里的目标任务有个特点就是可用的训练数据非常小,仅仅用目标任务自身的数据训练出的模型泛化能力非常差。
在这里我们引入域的概念,域的表达式如下 $D={\chi, P(X)}$ ,其中 $\chi$ 表示特征空间,$P(X)$ 表示边缘概率分布。引入源域 $D_S$ 和目标域 $D_T$ 的概念。且源域的大小要远远大于目标域。当源域和目标域的特征空间存在一些关系时,我们就认为这两个域是相关的。
在迁移学习中主要有三个问题:
1)迁移什么?
2)怎么迁移?
3)什么时候该迁移?
“迁移什么”是说在从源任务中迁移知识到目标任务时,哪些知识是可以迁移的?一般认为在源域中存在两种类型的知识,一种是源域特有的知识,一种是源域和目标域通用的知识,一般迁移的都是这类通用的知识。确定迁移的知识之后,就是“怎么迁移?”,也就是用什么算法进行知识的迁移。
“什么时候该迁移?”,确切的说就是在哪些场景下需要应用迁移学习,一般来说只有在源任务和目标任务之间存在相关性的时候才可以进行迁移学习。而在不相关的时候进行迁移时不会有任何效果,甚至可能会造成“负迁移”的后果。
基于上面关于迁移学习的定义,作者总结了不同场景下的迁移学习和传统机器学习的关系,具体如下表所示:

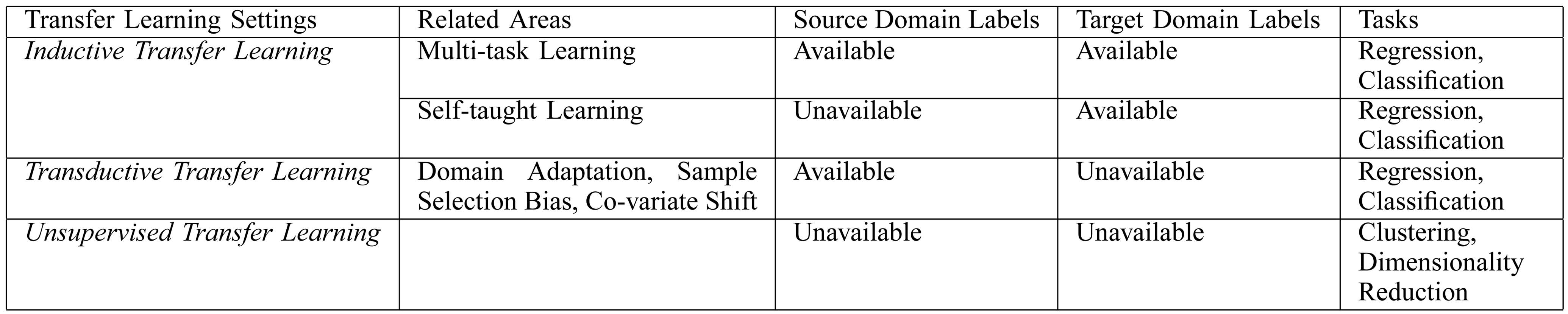
如上表所示,作者将迁移学习分为三种应用场景:Inductive Transfer Learning;Unsupervised Transfer Learning;Transductive Transfer Learning
1)Inductive Transfer Learning
在该场景下,源任务和目标任务分布不同但相关。该场景下需要根据目标域中少量可用的数据构建预测模型。该场景和多分类任务有点类似,知识迁移学习通过在源任务中提取相关的知识来提高目标任务的预测率,而在多分类任务中是将源任务和目标任务一起训练。
2)Unsupervised Transfer Learning
非监督迁移学习旨在解决聚类、密度估计等问题。
3)Transductive Transfer Learning
在该场景下,源域和目标域分布不同但是相关,而且有两种不同的情况:
a)源域和目标域的特征空间不同;
b)源域和目标域的边缘概率分布不同;
上述的三种场景下的迁移学习和相关应用领域的关系如下表所示:
上述的三种场景下的迁移学习可以被归结为四个案例中,具体如下表所示

上述表中四种案例分别是:
1)基于样本的迁移学习
源域中某一部分的数据通过施加权重后(相关性强的样本给予高权重),可以直接用来添加到目标域中直接学习目标任务,Tradaboost 算法就是这种类型的迁移学习。
2)基于特征的迁移学习
源域中数据的部分特征和目标域中相同,不如有一个猫狗的分类器可以用来迁移学习不同品种狗的分类器。
3)基于参数的迁移学习
源任务和目标任务共用相同参数的模型。或者是共用部参数或先验分布。
4)基于相关性的迁移学习
认为源域和目标域中的数据之间是具有相关性的迁移方式。
下表描述了四种不同案例可以使用的迁移方法。可以看到具体的案例可以用哪些迁移学习方法来解决。
